Automatisering av revisjon
I denne artikkelen vil vi presentere vår forståelse av potensiale og utfordringer med automatisering generelt, og i revisjon spesielt. Vi beskriver oppgaver med automatiseringspotensiale samt automatiseringsmuligheter og -utfordringer innen en bransje som revisjon.
Senior manager PwC

Direktør i PwC

Vi er nå inne i en lenge forespeilet potensiell automatiseringsrevolusjon, der teknologiske fremskritt i hva slags oppgaver som er mulige å automatisere er spådd. Det åpner nye muligheter i tradisjonelt analoge bransjer (ikke-digitale bransjer) samtidig som det utsetter etablerte analoge aktører for nye trusler fra «digital native»-konkurrenter.* Se f.eks. Harvard Business Review – Competing in the Age of AI (2020) for en oppsummering av en populær analyse av konsekvensene av teknologiske fremskritt innen automatisering og kunstig intelligens: https://hbr.org/2020/01/competing-in-the-age-of-ai For å utnytte de nye mulighetene – og ruste seg mot potensielle utfordrere – har det blitt jobbet mye med automatisering i tradisjonelt analoge bransjer de siste årene.
I første del beskriver vi fire generelle kjennetegn ved oppgaver med automatiseringspotensiale. Deretter tar vi utgangspunkt i kjennetegnene for å drøfte automatiseringsmuligheter og -utfordringer i eksempler fra revisjon. Til slutt ser vi på hvorfor mange automatiseringsinitiativ ikke lykkes med å skape varig forretningsverdi, og hvordan partnermodellen i de store revisjonsselskapene kan gjøre det ekstra utfordrende å realisere verdi fra automatisering.
Fire kjennetegn ved automatiserbare oppgaver
Når en jobber med automatisering og kunstig intelligens, gjelder det å holde hodet kaldt – det er ikke alle oppgaver som det er verdt å automatisere. Det er særlig fire kjennetegn ved oppgaver med stort automatiseringspotensiale:
1. Datagrunnlaget for oppgaven er tilgjengelig digitalt og (semi)strukturert
Både mennesker og automatiseringsløsninger trenger tilgang på relevante data for å utføre en oppgave, men mennesker og automatiseringsløsninger har forskjellige styrker når det gjelder datafangst. En menneskelig ekspert har hele sanseapparatet og kan lese, snakke, lytte, og (for håndverksoppgaver) føle seg frem til de nødvendige dataene, men det er begrenset hvor store datamengder han eller hun klarer holde i hodet på en og samme tid.
En automatiseringsløsning håndterer nær sagt vilkårlig store datamengder, men er prisgitt at dataene er tilgjengelig digitalt og noenlunde strukturert. De siste årene er det gjort store fremskritt i å trekke ut maskinell innsikt fra ustrukturerte data ved hjelp av maskinlæring, men godt strukturerte data gjør automatiseringsarbeidet enklere, billigere, og mer gjennomsiktig. Eksempler på kilder til strukturerte data er systemintegrasjoner (f.eks. kobling til regnskapssystemets-API), strukturerte filer (f.eks. SAF-T XML), og tilrettelagte tabeller i datavarehus. Eksempler på ustrukturerte data er filer der utformingen av dataene vi er på jakt etter ikke følger noen forutsigbar standard (f.eks. bilde av faktura, eller et skjønnsmessig utformet Excel-ark), muntlige utsagn, eller ansiktsuttrykket til en kunde.
Å tilgjengeliggjøre nye data er en kryssfunksjonell øvelse – den krever effektivt samarbeid mellom fagfolk og beslutningstagere som ofte er spredt ut over forskjellige «siloer» hos etablerte aktører. Dataenes eier(e) må bli enige om de forretningsmessige vilkårene for å gjøre dataene tilgjengelige, juridiske forhold (f.eks. personvern) må avklares, og den tekniske datafangstløsningen (f.eks. systemintegrasjonen) må bygges. I sum kan dette fort bli dyrt og tidkrevende, og de beste automatiseringskandidatene finnes ofte der (semi)strukturerte digitale data allerede er tilgjengelig.
2. Oppgaven utføres mange ganger, med få (forventede) endringer, i moderne digitale verktøy
Selv der strukturerte data er tilgjengelig, er det ofte betydelige kostnader knyttet til utvikling og drift av automatiseringsløsninger: Beslutningsmodeller skal bygges, overvåkningssystemer skal settes opp, og prosesser for å håndtere avvik og feilbeslutninger må på plass. Prototyping og pilotering av automatisering er forholdsvis enkelt, men utvikling, produksjonssetting og drift av skalerbare automatiseringer – som er stabile og robuste nok til å tåle høy og langvarig bruk – krever bred og kostbar kompetanse.*Forretning/domenekunnskap, prosessforbedring/lean, jus, design, data engineering, avansert analyse & maskinlæring, front end- og back end-utvikling, testing, cloud, devops, m.m. Kryssfunksjonelt samarbeid innebærer ofte krevende endringer i prosesser og organisering. I tillegg kan automatisering medføre nye operasjonelle risikoer og at en må etterleve flere regulatoriske krav. Dette gjelder særlig automatisering av beslutninger som får konsekvenser for enkeltmennesker, eller som involverer analyser og modellering på datasett som inneholder personopplysninger.*Datatilsynets rapport Kunstig Intelligens og personvern (2018) gir en god oversikt over hvordan personvern blir berørt av automatisering og kunstig intelligens, og hvilke regler som gjelder https://www.datatilsynet.no/globalassets/global/dokumenter-pdfer-skjema-ol/rettigheter-og-plikter/rapporter/rapport-om-ki-og-personvern.pdf Oppgaver som automatiseres, må utføres i tilstrekkelig stort volum og uten store endringer over tid for at investeringen skal gå i pluss. En må også hensynta hvordan oppgaven faktisk utføres når de nødvendige (automatiske) beslutningene er tatt. Oppgaver som utføres i digitale verktøy med gode integrasjonsmuligheter, lar seg for eksempel enklere automatisere enn oppgaver som utføres fysisk, analogt, eller i gamle digitale verktøy med begrensede integrasjonsmuligheter.
3. Vurderingene som inngår i oppgaven er spesifikke og (relativt) enkle
I dag presterer algoritmisk maskinlærte beslutningsmodeller ofte bedre enn menneskelige eksperter på problemstillinger som kan spesifiseres eksakt og tydelig avgrenses og isoleres fra andre nærliggende vurderinger og problemstillinger. Jo større behov det er for å tenke helhetlig, generalisere lærdom fra ett område over på et annet, og se ting i sammenheng, jo svakere presterer maskinlæringsmodeller sammenlignet med menneskelige eksperter.
En god tommelfingerregel er at en oppgave bør kunne brytes opp i en serie selvstendige enkeltvurderinger som hver for seg er så enkle at en menneskelig ekspert med relevante data tilgjengelig kan fatte en veloverveid beslutning i løpet av ett sekund.*https://hbr.org/2016/11/what-artificial-intelligence-can-and-cant-do-right-now Der dette ikke er mulig, kan kostnaden for å bygge og vedlikeholde en tilstrekkelig treffsikker beslutningsmodell fort bli større enn automatiseringsgevinsten.
4. Det er mulig å definere et objektivt og kvantifiserbart mål på om en beslutning har vært vellykket
Den vanligste måten å bygge maskinlærte beslutningsmodeller på er å mate en algoritme med store mengder data om hvordan en oppgave har blitt utført tidligere. For hver vurdering i slike «treningsdata» må algoritmen vite beslutningsgrunnlaget «X» som var tilgjengelig på vurderingstidspunktet, og fasiten «Y»: den beslutningen som, ofte i etterpåklokskapens lys, skulle vise seg å være rett for denne konkrete vurderingen. Basert på dette jobber algoritmen frem en generell beslutningsmodell for hvis-X-så-Y.
Slike treningsdatasett er ikke alltid rett frem å konstruere. Ofte kan man hente ut og/eller rekonstruere tilgjengelig informasjon X for hver tidligere utførte oppgave, og tilsvarende om hvilken beslutning som ble tatt. Om denne beslutningen faktisk var riktig, kan være langt vanskeligere å fastsette.
Bilagskontroll er et illustrerende eksempel: For hvert enkelt bilag er det enkelt å hente beslutningsgrunnlaget slik det forelå på beslutningstidspunktet, og data om bilaget ble besluttet kontrollert eller ei. Om det var riktig vurdering å kontrollere (eller ikke kontrollere) er en annen sak – er bilaget kontrollert og vurdert ok kan likevel en feil eller mangel ha blitt oversett. Ble bilaget ikke kontrollert, får man som regel ikke vite hva utfallet eventuelt ville blitt. Se figur 1.
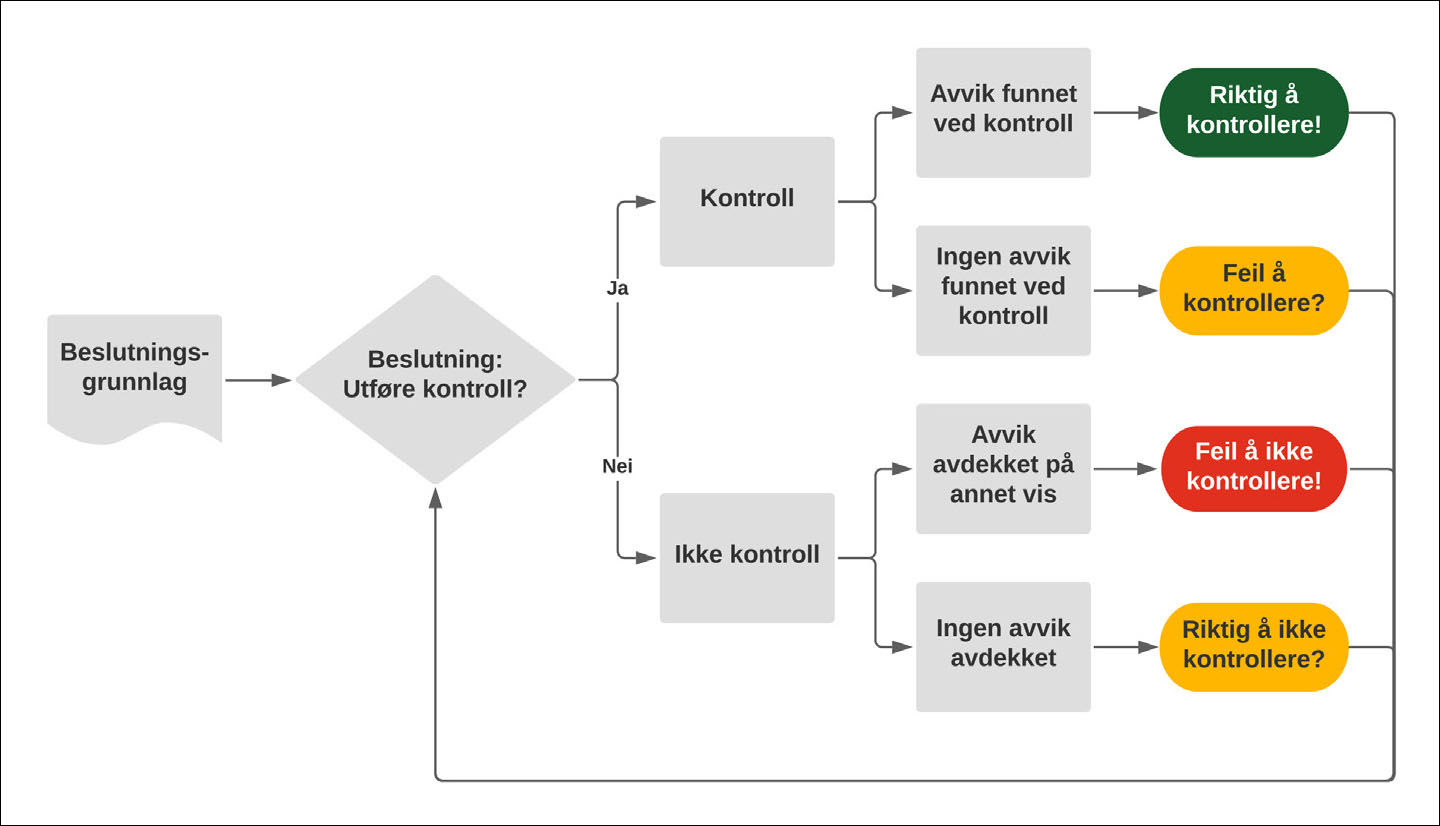
Figur 1: Maskinlærte beslutningsmodeller bygges («trenes») ofte på historiske data om hvordan tilsvarende beslutninger har blitt gjort tidligere. For å bygge gode modeller bør man kunne definere et mål på hvorvidt de tidligere beslutningene har vært vellykket.
En ofte brukt snarvei er å definere «vellykket beslutning» som «den beslutning våre menneskelige eksperter ville tatt». Da blir målet for modellen enkelt: Å gjenskape tidligere menneskelige beslutningsmønstre, dog med alle de eventuelle svakheter, blindsoner, og bias som måtte ligge deri. Noen ganger er dette et pragmatisk sted å begynne, men det er fort gjort å trå feil. Amazons modell for screening av jobbsøkere*Se https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G og https://becominghuman.ai/amazons-sexist-ai-recruiting-tool-how-did-it-go-so-wrong-e3d14816d98e er et klassisk eksempel på hvordan dette kan gå galt: I Amazons historiske data hadde kvinner sjelden fått jobbtilbud, og uten andre føringer fant algoritmen frem til en beslutningsmodell der kvinner generelt scoret lavt, det fremgikk jo av de historiske dataene at de uansett sjelden fikk jobb. En automatiseringsløsning kan gjøre beslutninger i mye større volum enn et menneske, derfor vil det ofte stilles strengere krav til forståelsen av hvorvidt beslutninger er riktige enn «løsningen skal gjøre de samme vurderingene som de menneskelige ekspertene tidligere har gjort.»*Personvernforordningens artikkel 22 er et godt eksempel på hvordan det stilles høyere krav til beslutninger tatt av datamaskiner enn beslutninger tatt av mennesker, https://www.datatilsynet.no/rettigheter-og-plikter/den-registrertes-rettigheter/rettar-ved-automatiserte-avgjerder/
Automatiserbare oppgaver i revisjon
La oss nå anvende kjennetegn-reglene på en klassisk revisjonsoppgave – kontroll av skattemeldingen. Dette er en vanlig revisjonshandling i forbindelse med revisors signering av næringsoppgaven: Revisor kontrollerer tallene i skattemeldingen mot reviderte saldobalanser og annet relevant grunnlag, at de er internkonsistente, og at de samsvarer med fjorårets skattemelding.
Vi begynner med å dele oppgaven inn i sine enklere bestanddeler, jf. kjennetegn 3. Hva slags oppdeling som er hensiktsmessig, vil variere fra oppgave til oppgave. Et generelt godt utgangspunkt – som også ofte fungerer bra i revisjon – er de fire overordnede oppgavekategoriene: 1) samle og tilgjengeliggjøre data, 2) gjøre data om til innsikt, 3) konkludere basert på data og innsikt, og 4) handle i tråd med konklusjonen.*Kategoriene er inspirert av Agrawal et al, Prediction Machines (2018), som bryter en generisk oppgave opp i Input, Prediction, Judgement, og Action (samt feedback-loop for læring, ref. kjennetegn 4.) De fire oppgavekategoriene beskrives nærmere nedenfor.
1. Samle og tilgjengeliggjøre relevante data
I denne kategorien finner vi aktiviteter knyttet til innhenting og tilgjengeliggjøring av relevante data for oppgaven. Eksempler på datakilder for kontroll av skattemeldingen er:
Utkast til årets skattemelding fra revidertes årsoppgjørs-system
Fjorårets endelige skattemelding fra Altinn/Skatteetaten
Tradisjonelt innebærer datafangsten at revisor ser gjennom årets og fjorårets skattemeldinger og møysommelig leser av verdiene i de forskjellige postene manuelt.
Den beste måten å automatisere innhenting av slike data på er å bygge integrasjoner som lar dataene flyte direkte fra digitale datakilder (f.eks. årsoppgjørssystemer og Altinn) til datakonsumenten (f.eks. et revisjonssystem), men dette fordrer at kildesystemene har gode API-er en kan koble seg til.
Er dataene kun tilgjengelige som filer, kan datafangsten likevel automatiseres ved å bygge løsninger som gjenkjenner strukturene og automatisk henter ut de relevante verdiene fra filene. For godt strukturerte filformater (f.eks. XML*Saldobalanse og hovedbok er to sentrale datasett i revisjonen. Disse har tradisjonelt blitt sendt til revisor på epost eller overlevert på minnepinne, eksportert fra revisjonskundens regnskapssystem, på et format som kan variere fra system til system og oppdrag til oppdrag. Dette gjør at revisor ofte bruker uforholdsmessig mye tid og kapasitet på datainnhenting og -bearbeiding. I Revisjon & Regnskap nr. 1 2021 skriver vi om mulighetene en vellykket implementering av SAF-T XML-standarden for regnskapsdata åpner opp for revisor.) er dette relativt rett frem. Mindre strukturerte filformater (f.eks. regneark, eller skjema i PDF-format) øker kompleksiteten og risikoen for feil. Avhengig av volum på oppgaven kan automatiseringsgevinsten da fort gå tapt i kompleksiteten ved utvikling og drift av automatiseringsløsningen, jf. kjennetegn 1 og 2.
2. Gjøre data om til innsikt
Avansert analyse og maskinlæring handler om å gjøre data om til innsikt. Aktuelle eksempler i revisjon er å benytte algoritmisk genererte risikoprediksjoner som innsiktsgrunnlag for risikobasert utvalg, og sammenligning av revidertes regnskapstall med forventningstall beregnet på forhånd med statistiske metoder.
Innsikt kan også skapes med enklere metoder. I vårt eksempel med kontroll av skattemeldingen kan man programmere et sett med erfaringsbaserte «ekspertregler» for hvordan tallene i årets og fjorårets skattemelding bør henge sammen for at revisor skal være fornøyd. En automatisk generert rapport basert på disse reglene er nyttig innsikt for revisor når skattemeldingen skal kontrolleres.
3. Konkludere basert på data og innsikt
Kjernen i å jobbe datadrevet er å benytte data og innsikt generert fra dataene ved hjelp av analyser og/eller algoritmer – på en verdiskapende måte i beslutninger. Men selv tungt datadrevne beslutninger vil ofte involvere et element av menneskelig skjønn og ekspertvurdering. En maskinlæringsalgoritme med tilgang til de rette dataene kan gi en treffsikker prediksjon på sannsynligheten for at avvik vil oppdages ved kontroll av et bilag, men det er opp til revisor å veie kostnaden av unødvendige kontroller opp mot konsekvensen av at avvik forblir uoppdaget.
Ved kontroll av skattemeldingen må revisor beslutte hvordan innsikten fra de automatiske sjekkene skal benyttes. Kan skattemeldingen noteres som ok dersom de automatiske sjekkene er bestått? Dersom kontrollene avdekker et mindre avvik, skal det aksepteres som uvesentlig, eller kan det være toppen av et isfjell som bør undersøkes nærmere? Slike konklusjoner, som krever evne til å tenke helhetlig og ofte krever dyp kjennskap til kunde og bransje, er oppgaver som er krevende å automatisere med dagens teknologi.
4. Handle i tråd med konklusjonen
Data, innsikt, og konklusjoner er vel og bra. Det er først når de fører til handling at det skapes verdi. Revisors verdiskapende handlinger er å bekrefte det som stemmer, avdekke det som ikke stemmer, og å gi objektive råd om regler og ulike løsninger som ikke truer revisors uavhengighet. Det er stort spenn i potensialet for automatisering av revisors verdiskapende handlinger.
De lavthengende fruktene for handlingsautomatisering er produksjon av nødvendig dokumentasjon av revisjonshandlingene, både strukturert i revisjonssystem-databaser, og mer ustrukturert (men menneske-lesbart) i tekstdokumenter, regneark, og presentasjoner. Dersom vårt eksempel med automatisk kontroll av skattemeldingen avdekket avvik, kunne rapporten som dokumenterer funnene som gjør at revisor ikke kan signere næringsoppgaven fint genereres automatisk – men dialogen med foretakets økonomisjef om at det var slik det måtte bli, vil nok føres av menneskelige revisorer en stund til.
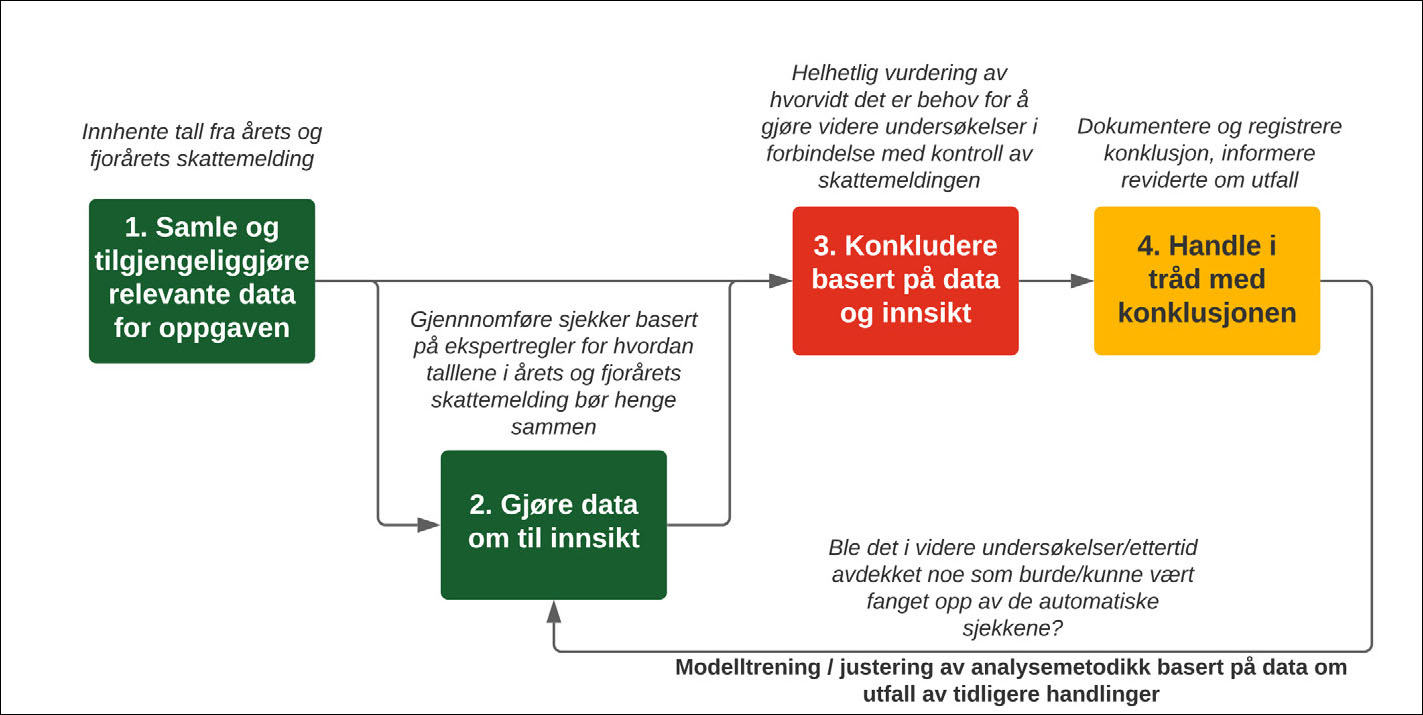
Figur 2: Revisors kontroll av skattemeldingen kan deles opp i en sammenhengende serie oppgaver der mange har lav kompleksitet. Det er stort potensiale for automatisering, særlig for oppgaver i kategoriene 1. Samle og tilgjengeliggjøre data, 2. Gjøre data om til innsikt, og 4. Handle.
Automatisering er aldri enkelt
De siste årene har PwC og andre gjennomført undersøkelser av hvorvidt investeringer i automatisering og kunstig intelligens gir positiv avkastning på kort/mellomlang sikt, og resultatene kan være nedslående for teknologioptimister.*MIT Sloan Review, Winning with AI (2019): «Seven out of 10 companies surveyed report minimal or no impact from AI so far. Among the 90 % of companies that have made some investment in AI, fewer than 2 out of 5 report business gains from AI in the past three years. This number improves to 3 out of 5 when we include companies that have made significant investments in AI. Even so, this means 40 % of organizations making significant investments in AI do not report business gains from AI.» https://sloanreview.mit.edu/projects/winning-with-ai/PwC & Carnegie Mellon University, Why Most Organizations’ Investments in AI Fall Flat (2020): «76 % of organizations surveyed barely broke even with their investments in AI capabilities. Only 6 % had AI initiatives scaled across the enterprise», https://hbr.org/sponsored/2020/10/why-most-organizations-investments-in-ai-fall-flat Selskap som gjør begrensede kortsiktige investeringer i automatisering, rapporterer sjelden realisert verdi. Selv blant selskapene som foretar betydelige investeringer, rapporterer nær halvparten lite eller ingen realisert verdi. Hva er det som gjør det så vanskelig å lykkes med automatisering?
En universell utfordring – uansett bransje – med å realisere verdi fra automatisering og kunstig intelligens er at en god automatiseringsløsning krever tett samarbeid mellom fagområder som ofte er organisert i separate siloer:
Forretnings- og fagkunnskap er avgjørende for at automatiseringsløsninger skal løse de riktige oppgavene og skape faktisk verdi. Uten tilstrekkelig forretnings- og fagforståelse er risikoen stor for å bygge automatiseringsløsninger som løser oppgaver med lav/ingen reell forretningsverdi, eller på sviktende faglig grunnlag.
Dersom oppgaven som skal automatiseres påvirker enkeltmennesker og/eller involverer behandling av personopplysninger, er det behov for kompetanse på personvern, både med juridiske og omdømmemessige briller. Uten slik kompetanse er risikoen stor for å utføre databehandling og analyser uten tilstrekkelig forståelse og dokumentasjon av juridisk behandlingsgrunnlag, og/eller implementere automatiseringsløsninger som ikke består «VG-testen».*«VG-testen»: Hvis du i selskap A vurderer å automatisere oppgave X, still deg følgende spørsmål: Hvordan vil du reagere dersom en journalist ringer og ber om kommentar til morgendagens førstesideoppslag «Robotene kommer! I selskap A er det nå datamaskiner som gjør X!»?
Analyseforståelse er nødvendig for å sikre kvaliteten på dataene som fanges inn og innsikten som skapes fra den; at analyser og maskinlæringsmodeller bygges på riktig måte på riktige data. Uten tilstrekkelig analyseforståelse er risikoen stor for å fatte beslutninger på feilaktig datagrunnlag og/eller upålitelig innsikt.
IT-utvikling og -drift – og kjennskap til fagsystemer og overordnet IT-arkitektur – er nødvendig for å produksjonssette automatiseringsløsninger på en skalerbar og forsvarlig måte. For (del)automatiseringsløsninger som fungerer som støtteverktøy i en menneskedrevet «human in the loop»-prosess, er det spesielt viktig med kompetanse som sikrer at løsningene designes og bygges på en måte som gjør at de tiltenkte brukerne opplever løsningene som brukervennlige og velger å benytte seg av dem.*I Nguyen og Pedersen, Revisors holdning til digitalisering i revisjon (2020) fant forfatterne at opplevd brukervennlighet veier tyngre enn opplevd nytteverdi for å få revisorer til å ta løsninger i bruk: «... Det var en sterkere sammenheng mellom oppfattet brukervennlighet til intensjon til faktisk bruk. Vårt bidrag til denne litteraturen foreslår at revisjonsselskapene bør fokusere på brukervennligheten av teknologien, før de sikrer revisors forståelse av nytten.»
Tre suksesskriterier
Det er skrevet mye om hva som kjennetegner selskap som lykkes med å ta i bruk automatisering og kunstig intelligens*For videre dypdykk i hvordan lykkes med kunstig intelligens, se PwCs Hva er kunstig intelligens, https://www.pwc.no/no/teknologi-omstilling/digitalisering-pa-1-2-3/kunstig-intelligens.html, McKinseys The data-driven enterprise of 2025, https://www.mckinsey.com/business-functions/mckinsey-analytics/our-insights/the-data-driven-enterprise-of-2025 og Executive’s guide to developing AI at scale https://www.mckinsey.com/business-functions/mckinsey-analytics/our-insights/executives-guide-to-developing-ai-at-scale – tre suksesskriterier vi vil trekke frem er:
evne og vilje til å investere tilstrekkelig og langsiktig i nødvendig prosess-standardisering, kompetanse og teknologi, og
felles forståelse i bedriften om verdien av å jobbe datadrevet,
som sammen muliggjørorganisering av arbeidet med automatisering og kunstig intelligens i kryssfunksjonelle autonome team med nødvendig kompetanse og mandat innenfor forretning/fag, jus, analyse, og IT.
Vår erfaring er at utfordringene med å få til effektivt samarbeid på tvers av siloer er minst like store som de rent tekniske utfordringene knyttet til datafangst, analyse, og produksjonssetting.
Avslutningsvis skal vi se på noen revisjons- og partnerorganisasjonsspesifikke utfordringer med å realisere verdi fra automatisering.
Automatisering i partnerorganisasjoner har unike tilleggsutfordringer
De ovennevnte utfordringene er generelle på tvers av bransjer. I Revisjon og Regnskap nr. 4 2021 stiller lederne for NHHs forskningsprosjekt DigAudit spørsmålet om den digitale omstillingen i revisjon går fort nok, og om hvordan barrierene mot omstilling kan bygges ned. De peker på at revisjonsbransjen har spesielle utfordringer knyttet til gjennomregulering og tilsyn, og at oppdragsansvarlig revisor ikke har sterke incentiver og kan også ha bevisst eller ubevisst motstand mot å ta i bruk nye analytiske verktøy og teknikker.*Eilifsen og Kinserdal, Digitalisering i revisjonsbransjen, Revisjon og Regnskap nr. 4 2021, https://www.revregn.no/journal/2021/4/m-1609/Digitalisering_i_revisjonsbransjen/ I det følgende vil vi belyse to strukturer ved revisjon som skaper incentiver mot bruk av – og investering i – automatisering i revisjon.

Revisjon omfatter mange oppgaver med høyt automatiseringspotensiale, men det krever langsiktige investeringer, bred forankring for å jobbe datadrevet, og utvikling og drift av automatisering i kryssfunksjonelle autonome team. Det er ikke bare å trykke på knapp …
For revisjonsselskap og andre partnerorganisasjoner er det to tilleggsutfordringer som må håndteres for å lykkes med å hente ut verdi fra automatisering: 1) Utjevning/fordeling av gevinster og kostnader ved bruk av automatisering, og 2) Incentivering av langsiktige teknologiinvesteringer ved «naken inn – naken ut»-organisering.
Det som er best for den enkelte partner, er ikke alltid det som er best for revisjonsselskapet
Totalkostnaden K for å levere et stykke revisjonsarbeid kan skrives som summen av 1) produksjonskostnaden P – kostnadene knyttet til arbeid og bruk av kapital for å gjennomføre revisjonsarbeidet – og 2) E – erstatningsutbetalinger og/eller tap av omdømme dersom det senere avdekkes forhold som skulle vært fanget opp i revisjonen.
Dersom en ser på alt revisjonsarbeid som utføres i et selskap, vil P og E ha forskjellige fordelinger: Produksjonskostnaden for et gitt revisjonsarbeid av en gitt kvalitet varierer relativt lite, og vil ligge nær en gjennomsnittverdi. Kostnadene E knyttet til erstatningsutbetalinger og tap av omdømme vil for mange enkeltarbeid være lik 0, mens snittet dras opp av det mindre antallet arbeider der svikt ved revisjonen forekommer og får konsekvenser, se figur 3.
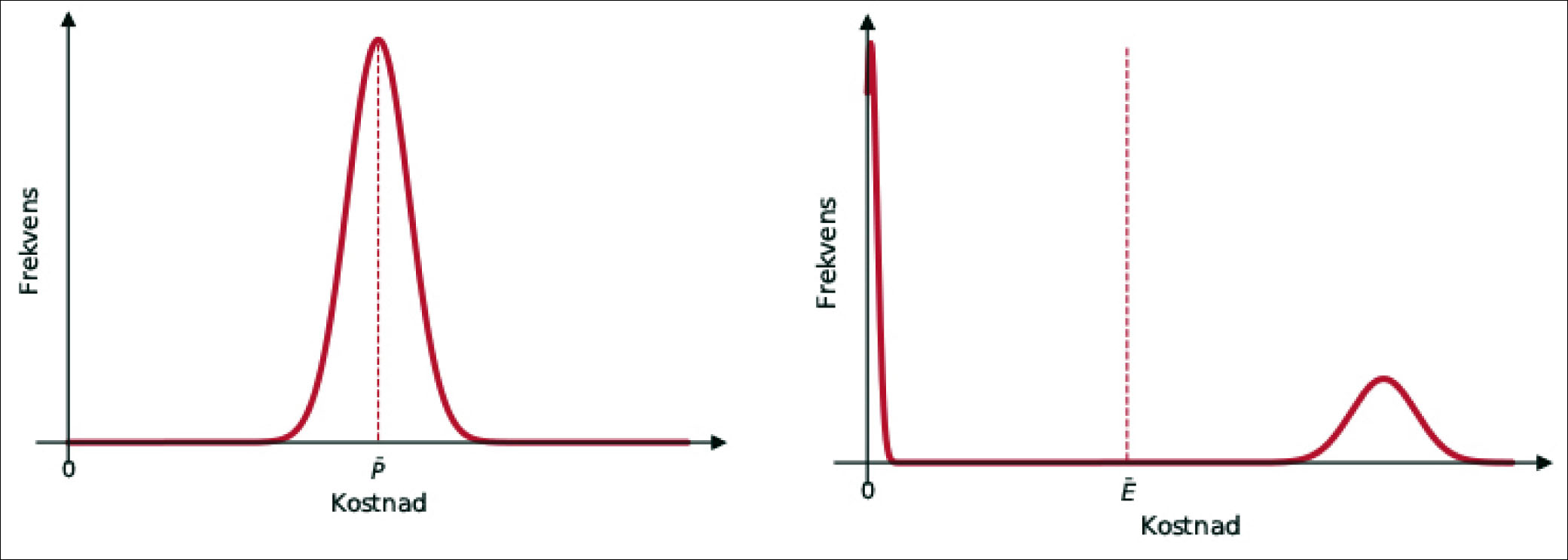
Figur 3: Produksjonskostnaden P for et gitt revisjonsarbeid varierer lite rundt en gjennomsnittsverdi. Erstatnings- og omdømmekostnaden E vil være 0 for revisjonsarbeid der det ikke avdekkes svikt, og potensielt meget høy for de få arbeid der svikt avdekkes. Gjennomsnittskostnaden ligger et sted imellom. Et revisjonsselskap som utfører en stor mengde revisjonsarbeid, har mulighet til pragmatisk å forholde seg til gjennomsnittskostnaden. For den enkelte partner kan det imidlertid få store konsekvenser å stå ansvarlig for arbeid som medfører erstatnings- og omdømmekostnader.
Automatisering påvirker produksjonskostnaden P og erstatning/omdømme-kostnaden E på forskjellige måter, avhengig av valgt strategi for å realisere verdi fra automatiseringen:
Effektivisering
Dersom gevinsten hentes ut gjennom effektivisering, synker produksjonskostnaden P, men automatisering for å øke effektiviteten vil ofte innebære en økning i (risiko for) erstatnings/omdømme-kostnader E. For revisjonsselskapet som helhet er ikke dette nødvendigvis problematisk – så lenge reduksjonen i gjennomsnittlig produksjonskostnad overstiger eventuelle økninger i gjennomsnittlig erstatning/omdømme-kostnad, og selskapet utfører et tilstrekkelig stort antall revisjonsarbeid, vil de store talls lov*Enkelt formulert sier de store talls lov at jo flere tilfeller man har av en hendelse, jo nærmere vil man komme det forventede resultatet. Se https://no.wikipedia.org/wiki/Store_talls_lov sikre at automatiseringen i sum reduserer totalkostnaden.
Partneren har et annet utgangspunkt
For den enkelte revisjonspartner er ikke regnestykket like enkelt. Automatiserings forårsaket svikt treffer ofte tilfeldig, og for partneren som står ansvarlig for revisjonsarbeidet der bruken av automatisering tilfeldigvis har ført til erstatningsutbetalinger og omdømmetap, er det en mager trøst at selskapet som helhet på sikt vil tjene på at løsningen brukes – spesielt dersom markedets og regulatoriske myndigheters syn på bruk av automatisering i revisjon oppleves uavklart. Da er det tryggeste å «snu bunken» og gjøre som i fjor.
Brukervennlighet, gjennomsiktighet og forklarbarhet i hvordan automatiseringsløsninger fungerer, regulatoriske og markedsmessige avklaringer, og tydelig definerte risikoscenarier og -tiltak, er viktige virkemidler for å sikre trygghet ved – og bruk av – effektiviserings-automatisering i revisjonsarbeid.
Kvalitetsheving
Automatiseringsløsninger kan også bygges med kvalitetshevingsom primær verdirealiseringsstrategi. Her oppstår det motsatte problemet: Kvalitetsheving kan på sikt forbedre gjennom reduksjon av erstatningsutbetalinger og/eller styrket omdømme, men kvalitetsheving-automatisering vil også ofte innebære en økning i produksjonskostnad. Revisjonsselskapet som helhet kan komme til at en økning i gjennomsnittlig produksjonskostnad er en pris det er verdt å betale for å heve kvaliteten i revisjonsarbeidet utover dagens regulatoriske og markedsmessige forventninger. Men omdømme-gevinsten ved kvalitetsheving tar tid å realisere, og treffer alle revisorer i selskapet likt, uansett om de har bidratt til å skape den eller ikke. En revisjonspartner må tenke solidarisk og langsiktig på selskapets beste for å velge å benytte produksjonskostnadsdrivende kvalitetshevende automatiseringsløsninger på sine revisjonsoppdrag, når en ved å følge veletablert tradisjonell revisjonsmetodikk uansett vil ha «ryggen fri» dersom det skulle avdekkes forhold som potensielt kunne vært oppdaget gjennom automatisert datafangst og -innsikt.
Gamle partnere får ikke høste fruktene av langsiktige investeringer
Blant de store revisjonsselskapene er partnermodeller utformet etter «naken inn – naken ut»-prinsippet dominerende – partnere som trer inn i revisjonsselskapet betaler ikke for goodwill, teknologi, og andre verdier som finnes i selskapet når de trer inn som eiere, men får heller ikke betalt for eventuelle verdiøkninger når de senere trer ut.
Tunge og langsiktige løsninger
Automatiseringsløsninger kan utgjøre store verdier, men krever ofte tunge og langsiktige investeringer for å lykkes: Prosesser må endres og standardiseres, nye kompetansemiljøer må opprettes, teknisk infrastruktur må bygges, og nye risikoer må håndteres. Vellykkede automatiserings-investeringer vil øke avkastning på lang sikt, men på kort sikt svekker slike investeringer partnernes løpende avkastning. For partnere med kort tid igjen til de skal forlate selskapet «naken ut» vil deltagelse i langsiktige teknologiinvesteringer i praksis utgjøre en uselvisk sponsing av yngre partnernes potensielle fremtidige økning i avkastning. Samtidig er det ofte disse erfarne partnerne som har størst innflytelse på selskapets strategiske veivalg, se figur 4.
«Naken inn – naken ut»-modellen
«Naken inn – naken ut»-modellen gir derfor et incentiv til å prioritere begrensede investeringer med håp om rask verdirealisering fremfor tyngre investeringer med langsiktig horisont og større potensiell oppside. Det er viktig å være klar over denne problemstillingen og å ha en omforent strategi for å håndtere den før en går i gang med automatiseringsarbeid i revisjon – spesielt sett i lys av ovennevnte funn om at evne og vilje til å investere tilstrekkelig tungt og langsiktig er et viktig kjennetegn på de som lykkes med å realisere verdi fra automatisering på en skalerbar måte.
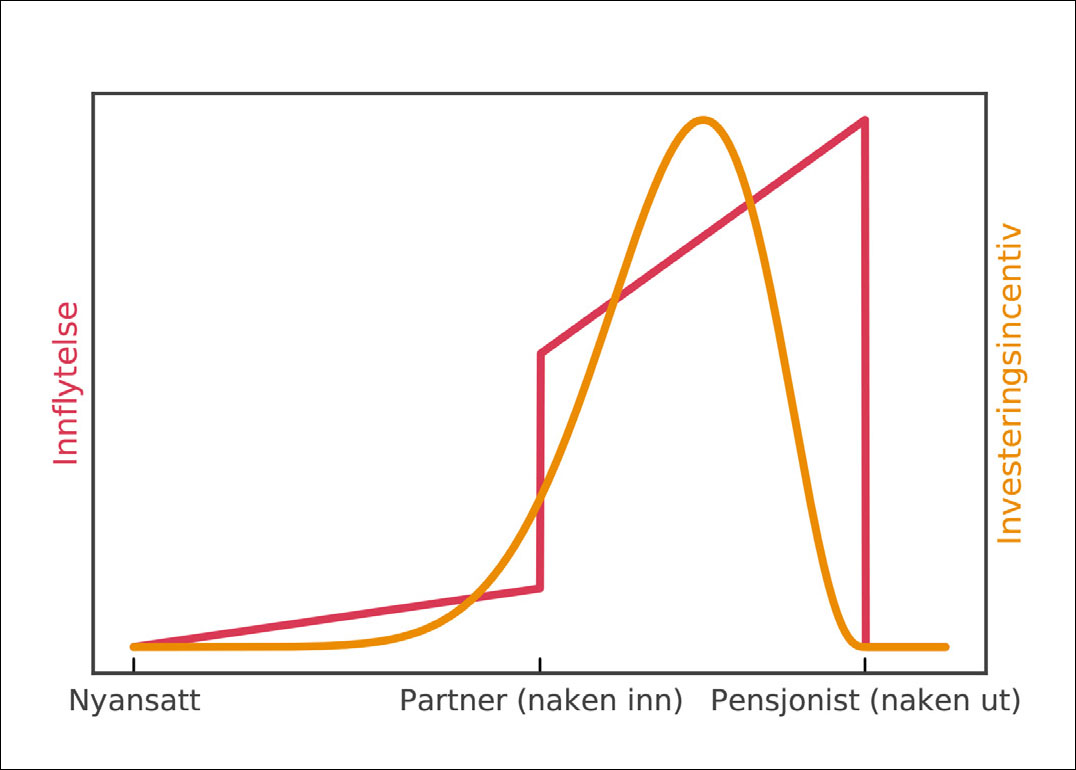
Figur 4: Partneres erfaring og innflytelse øker med alder, omvendt proporsjonalt med gjenværende tid før de skal selge seg ut av selskapet. »Naken inn, naken ut«-modellen fører til at eierne med mest erfaring og innflytelse er de som har minst incentiv for å investere langsiktig i ny teknologi.
Strategi og målbilde for automatisering av revisjon er avgjørende
En oppgave er velegnet for automatisering dersom den har strukturerte data tilgjengelig, utføres i tilstrekkelig stort volum på en stabil og strukturert måte, kan brytes opp i enkle, spesifikke og uavhengige vurderinger, og det lar seg gjøre å definere et mål for feedback på om vurderingene blir gjort riktig.
Revisjon omfatter mange oppgaver med høyt automatiseringspotensiale, spesielt innen datafangst, generering av innsikt fra data, og dokumentasjon av utført arbeid.
Fellesnevnere for selskap som lykkes med å realisere verdi fra automatisering er langsiktige investeringer, bred forankring for å jobbe datadrevet, og utvikling og drift av automatisering i kryssfunksjonelle autonome team.
Ansvars- og partnermodellen i revisjon skaper incentiver mot å investere i og ta i bruk automatiseringsløsninger. Dette gjør det ekstra viktig å ha tydelig og omforent målbilde og strategi for hvordan en som revisjonsselskap ønsker å utforske, utvikle, implementere, håndtere risiko, og realisere verdi fra automatisering av revisjon.