
Automatiseringen av et kundesenter
Hovedutfordringen for et kundesenter var at mye av tiden gikk med til å besvare enkle funksjonsspørsmål, samt løse problemer som passordbytte og etablere nye brukere i systemene. Slik automatiserte vi mesteparten av prosessen.

Siviløkonom/revisor
Divisjonsdirektør i Visma IT & Hosting

Ingeniør
Leder for prosessautomatiseringsavdelingen i Visma ITC

Sivilingeniør Peter Sandberg i Visma er hovedutvikler av systemet og har monitoring-systemet i bakgrunnen.
I tillegg til at mye tid ble brukt på enkle spørsmål, var kommunikasjonen mellom kunde og kundesenter bare delvis systematisert, slik at det var behov for å vurdere og optimalisere både kommunikasjonsprosessen og de verktøyene som ble brukt. Hele prosessen og de verktøyene som ble brukt, måtte derfor vurderes og optimaliseres.
Delprosjekt 1 – kanaler
En god supportopplevelse starter med at det finnes enkle og strømlinjede måter en bruker kan kontakte supporttjenesten på.
Det er derfor naturlig å starte med en klar strategi for hvilke kanaler som kan brukes og, ikke minst, hvilke kanaler selskapet ønsker at en kunde skal bruke.
Første del av prosjektet gikk derfor ut på å finne den optimale miksen av kanaler.
Ved å benytte skytjenester gikk kontaktmønsteret til kundene mer over på chat og mail fra telefon. Dette fant vi ut ved å gjøre en analyse av brukeradferden i vårt største supportsenter (200 konsulenter). Over tid var det en relativt kraftig nedgang fra telefonsamtaler over til chat. Spesielt gjaldt det kunder som flyttet over til skybaserte tjenester, der nesten 100 % flyttet over til chat.
Denne delen av prosjektet endte med at følgende kanaler ble gjort tilgjengelig for kundene:
Mail – åpent 24/7/365
Chat – åpent 0800–16.00 og 24/7/365 (chatbot)
Telefon – åpent 08.00–16.00
Fordelen med å flytte fokus over på mail og chat er at all kommunikasjon blir digitalisert for videre analyse og forbedring av hele tjenesten. I tillegg kan flere kunder hjelpes på samme tid.
Dette var derfor ett av nøkkelpunktene for å automatisere kundetjenesten.
Del 2 – initiell klassifisering
Etter at første del var klar, hadde vi samlet en rekke eksempler på hvordan diverse saker kan løses. Vi jobbet videre med å dele strømmen av henvendelser til to systemer for klassifisering og mulige svar. Det første systemet var en middels avansert chatbot som skulle svare på enkle spørsmål hele døgnet. Typiske spørsmål som: – hvordan skal jeg kontere en post eller videresende en faktura i et ERP-system, ble håndtert av denne.
Kundene hadde mulighet til å sammenstille en hel samtalelogg og sende denne til videre behandling hvis tjenesten ikke kunne svare. Dette var starten på den mer avanserte kvalifiseringstjenesten som jobbet med avansert tekstklassifisering og koding av henvendelsen.
Avansert tekstklassifisering bruker blant annet algoritmetyper som Support Vector Machine (SVM) (er spesielt egnet til tekst), mens andre typer av algoritmer ble brukt for å lage en mest mulig optimalisert modell.
Sammen med en operasjonell modell bygd ene og alene i vår anbefalte skyplattform, Amazon Web Services, kunne tjenesten etterhvert klassifisere en middels til avansert henvendelse på 1–3 sekunder, mer enn nok for vårt volum.
Del 3 – anbefaling
Den samme tjenesten som klassifiserer henvendelser, kan ved å knytte seg til flere datakilder utvide sin funksjonalitet.
La oss for eksempel si at din bedrift har et system for å skrive guider for typiske funksjoner i en applikasjon, og hvordan man løser et problem i en annen. Dette kan f.eks. være at man oppretter en ny kunde i ett ERP system eller sender skatteoppgjør til Altinn fra tjenesten.
Er dette systemet opprettet riktig og samtidig har en kobling til systemet som brukes for kundehenvendelser, er det mulig å koble nylig innkommede saker med en oppskrift for å løse disse.
Dette kalles et anbefalingssystem* https://en.wikipedia.org/wiki/Recommender_system og er samme type system som benyttes dersom du for eksempel handler bøker på Amazon eller abonnerer på NetFlix. NetFlix sitt anbefalingssystem sammenligner hva du tidligere har sett på og matcher det mot nylige opprettede titler.
På samme måte bruker vi systemet for å matche sannsynligheten for at et spørsmål kan besvares med et svar som er skrevet på forhånd.
Finnes det en match med en bestemt sannsynlighet, vil tjenesten anbefale at supportkonsulenten bruker fremgangsmåten slik den er beskrevet.
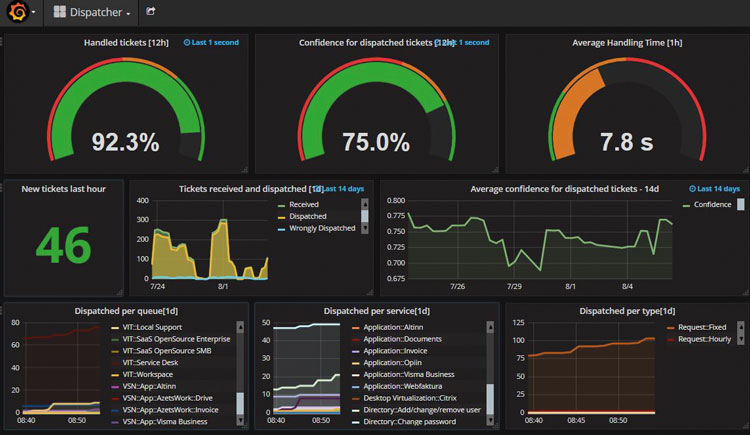
Monitoring-systemet viser til enhver tid hvor mange henvendelser som behandles automatisk, gjennomsnittlig behandlingstid, med hvilket presisjonsnivå/sikkerhetsnivå de forskjellige henvendelsene behandles osv.
Del 4 – utføring
Vi har på dette stadium i prosjektet sikret at de fleste henvendelsene til et kundesenter er digitaliserte, vi har løst de fleste av de enkle spørsmålene som forventes å komme og vi har klassifisert de resterende spørsmålene inn i forskjellige kategorier. I siste del av prosjektet har vi koblet til noen ekstra datakilder for å bruke samme modell som i del 2 for å anbefale løsninger til supportkonsulentene for å lette supporttjenestens arbeide.
Det som står igjen å gjøre, er å utføre det vi beskrev i del 3.
Så sant vi stoler på det vi produserte i del 3, kan vi for eksempel med enkle grep automatisere en oppgave som å legge til en bruker i en tilgangsliste eller gi en bruker utvidede rettigheter i samme applikasjon.
De foregående delene kan relativt enkelt verifisere at en slik bestilling er teknisk riktig, men å verifisere gyldigheten av den er litt mer utfordrende. Dette kan være å verifisere at det er nærmeste leder som har bestilt en ny datamaskin til en ansatt, eller at det er den riktige eieren av et system som har bestilt tilgang til systemet for en tredje person.
Vi tar derfor en kontroll på gyldigheten av bestillingen via en konsulent for å verifisere at den er gyldig.
Det vil være dypt problematisk om en ukjent part skulle klare å lure til seg en bestilling om tilgang til et ERP-system.
Vi skiller derfor mellom hvilke henvendelser som fullt ut kan automatiseres og hvilke som ikke kan.
Selve den tekniske gjennomføringen av dette kan gjøres på to måter:
Utvikling av små tjenester for gjennomføring, Microservices* https://en.wikipedia.org/wiki/Microservices
Mer brukervennlige, men dyrere, Robotic Process Automation(RPA)-systemer* https://en.wikipedia.org/wiki/Robotic_process_automation
Hva du velger her, styres i hovedsak av hvilke ressurser du råder over og hvor raskt du vil rulle ut nye fullautomatiserte henvendelser.
Oppsummering
Flere forhold avgjør hva en bedrift trenger av kunnskap og støttesystemer for å kunne gjennomføre en mer eller mindre automatisert supporttjeneste. Mye handler om kunnskap og det er meget viktig å ha en medarbeider som kan prosessmodellering og kjenner bedriften godt.
En dårlig prosess skaper uten unntak dårlig data.